I stumbled upon an
interesting question on Stack Overflow recently. A user wanted to query a table for a given predicate. If that predicate returns no rows, they wanted to run another query using a different predicate. Preferably in a single query.
Challenge accepted!
Canonical Idea: Use a Common Table Expression
We’re querying the
Sakila database and we’re trying to find films of length 120 minutes. If there are no such films, then let’s find films of length 130 minutes. The following query is formally correct and runs without any adaptations on all of Oracle, PostgreSQL and SQL Server (and probably on other DBs too, as it’s pretty standard):
WITH r AS (
SELECT * FROM film WHERE length = 120
)
SELECT * FROM r
UNION ALL
SELECT * FROM film
WHERE length = 130
AND NOT EXISTS (
SELECT * FROM r
)
How does it work?
The common table expression (
WITH clause) wraps the first query that we want to execute no matter what. We then select from the first query, and use
UNION ALL to combine the result with the result of the second query, which we’re executing only if the first query didn’t yield any results (through
NOT EXISTS). We’re hoping here that the database will be smart enough to run the existence check on a pre-calculated set from the first subquery, in order to be able to avoid running the second subquery.
Let’s see, which database actually does this.
PostgreSQL
Running
EXPLAIN ANALYZE…
EXPLAIN ANALYZE
WITH r AS (
SELECT * FROM film WHERE length = 120
)
SELECT * FROM r
UNION ALL
SELECT * FROM film
WHERE length = 130
AND NOT EXISTS (
SELECT * FROM r
)
… we can see the following plan:
Append (cost=68.50..137.26 rows=15 width=561) (actual time=0.052..0.300 rows=9 loops=1)
CTE r
-> Seq Scan on film film_1 (cost=0.00..68.50 rows=9 width=394) (actual time=0.047..0.289 rows=9 loops=1)
Filter: (length = 120)
Rows Removed by Filter: 991
-> CTE Scan on r (cost=0.00..0.18 rows=9 width=672) (actual time=0.051..0.297 rows=9 loops=1)
-> Result (cost=0.02..68.52 rows=6 width=394) (actual time=0.002..0.002 rows=0 loops=1)
One-Time Filter: (NOT $1)
InitPlan 2 (returns $1)
-> CTE Scan on r r_1 (cost=0.00..0.18 rows=9 width=0) (actual time=0.000..0.000 rows=1 loops=1)
-> Seq Scan on film (cost=0.00..68.50 rows=6 width=394) (never executed)
Filter: (length = 130)
Planning time: 0.952 ms
Execution time: 0.391 ms
So, indeed, the database seems to be smart enough to avoid the second query, because the first one does yield 9 rows.
Can we see this in a benchmark as well? In principle, the complete query should take about as much time in a benchmark as the Common Table Expression alone. Here’s the benchmark logic:
DO $$
DECLARE
v_ts TIMESTAMP;
v_repeat CONSTANT INT := 2000;
rec RECORD;
BEGIN
-- Repeat benchmark several times to avoid warmup penalty
FOR r IN 1..5 LOOP
v_ts := clock_timestamp();
FOR i IN 1..v_repeat LOOP
FOR rec IN (
SELECT * FROM film WHERE length = 120
) LOOP
NULL;
END LOOP;
END LOOP;
RAISE INFO 'Run %, Statement 1: %', r,
(clock_timestamp() - v_ts);
v_ts := clock_timestamp();
FOR i IN 1..v_repeat LOOP
FOR rec IN (
WITH r AS (
SELECT * FROM film WHERE length = 120
)
SELECT * FROM r
UNION ALL
SELECT * FROM film
WHERE length = 130
AND NOT EXISTS (
SELECT * FROM r
)
) LOOP
NULL;
END LOOP;
END LOOP;
RAISE INFO 'Run %, Statement 2: %', r,
(clock_timestamp() - v_ts);
RAISE INFO '';
END LOOP;
END$$;
The result is:
INFO: Run 1, Statement 1: 00:00:00.310325
INFO: Run 1, Statement 2: 00:00:00.427744
INFO: Run 2, Statement 1: 00:00:00.303202
INFO: Run 2, Statement 2: 00:00:00.33568
INFO: Run 3, Statement 1: 00:00:00.323699
INFO: Run 3, Statement 2: 00:00:00.339835
INFO: Run 4, Statement 1: 00:00:00.301084
INFO: Run 4, Statement 2: 00:00:00.343838
INFO: Run 5, Statement 1: 00:00:00.356343
INFO: Run 5, Statement 2: 00:00:00.359891
As you can see, the second statement is consistently slower by around 5% – 10%. So we can safely say, the second subquery looking for length = 130 is not executed, but there’s still some overhead compared to making a decision in a client application to avoid that second subquery entirely. My guess here is that this is due to PostgreSQL’s Common Table Expression (CTE) being “optimisation fences”, i.e. the CTE is materialised every time. See also:
https://blog.2ndquadrant.com/postgresql-ctes-are-optimization-fences/
What about the inverse case?
In the above benchmark, we’ve measured how much time it takes when the first query succeeds (and the second query should be avoided). What about the inverse case, where the first query doesn’t match any rows and we have to run another query?
Benchmark time!
DO $$
DECLARE
v_ts TIMESTAMP;
v_repeat CONSTANT INT := 2000;
rec RECORD;
BEGIN
-- Repeat benchmark several times to avoid warmup penalty
FOR r IN 1..5 LOOP
v_ts := clock_timestamp();
FOR i IN 1..v_repeat LOOP
FOR rec IN (
SELECT * FROM film WHERE length = 1200
) LOOP
NULL;
END LOOP;
FOR rec IN (
SELECT * FROM film WHERE length = 130
) LOOP
NULL;
END LOOP;
END LOOP;
RAISE INFO 'Run %, Statement 1: %', r,
(clock_timestamp() - v_ts);
v_ts := clock_timestamp();
FOR i IN 1..v_repeat LOOP
FOR rec IN (
WITH r AS (
SELECT * FROM film WHERE length = 1200
)
SELECT * FROM r
UNION ALL
SELECT * FROM film
WHERE length = 130
AND NOT EXISTS (
SELECT * FROM r
)
) LOOP
NULL;
END LOOP;
END LOOP;
RAISE INFO 'Run %, Statement 2: %', r,
(clock_timestamp() - v_ts);
RAISE INFO '';
END LOOP;
END$$;
The result is roughly the same:
INFO: Run 1, Statement 1: 00:00:00.680222
INFO: Run 1, Statement 2: 00:00:00.696036
INFO: Run 2, Statement 1: 00:00:00.673141
INFO: Run 2, Statement 2: 00:00:00.709034
INFO: Run 3, Statement 1: 00:00:00.626873
INFO: Run 3, Statement 2: 00:00:00.679469
INFO: Run 4, Statement 1: 00:00:00.619584
INFO: Run 4, Statement 2: 00:00:00.639092
INFO: Run 5, Statement 1: 00:00:00.616275
INFO: Run 5, Statement 2: 00:00:00.675317
A slight overhead in the single query case.
But what’s this? We didn’t even have an index on the
LENGTH column. Let’s add one!
Now, the result is very different. Query 1 succeeds:
INFO: Run 1, Statement 1: 00:00:00.055835
INFO: Run 1, Statement 2: 00:00:00.093982
INFO: Run 2, Statement 1: 00:00:00.038817
INFO: Run 2, Statement 2: 00:00:00.084092
INFO: Run 3, Statement 1: 00:00:00.041911
INFO: Run 3, Statement 2: 00:00:00.078062
INFO: Run 4, Statement 1: 00:00:00.039367
INFO: Run 4, Statement 2: 00:00:00.081752
INFO: Run 5, Statement 1: 00:00:00.039983
INFO: Run 5, Statement 2: 00:00:00.081227
Query 1 fails:
INFO: Run 1, Statement 1: 00:00:00.075469
INFO: Run 1, Statement 2: 00:00:00.081766
INFO: Run 2, Statement 1: 00:00:00.058276
INFO: Run 2, Statement 2: 00:00:00.079613
INFO: Run 3, Statement 1: 00:00:00.060492
INFO: Run 3, Statement 2: 00:00:00.080672
INFO: Run 4, Statement 1: 00:00:00.05877
INFO: Run 4, Statement 2: 00:00:00.07936
INFO: Run 5, Statement 1: 00:00:00.057584
INFO: Run 5, Statement 2: 00:00:00.085798
Oracle
In Oracle, I couldn’t find any difference in execution speed (see below). The plan of a combined query also contains an element that prevents the execution of the second subquery. In this case, I’m using the
/*+GATHER_PLAN_STATISTICS*/ hint to make sure we get actual execution values / times in our execution plan:
WITH r AS (
SELECT * FROM film WHERE length = 120
)
SELECT /*+GATHER_PLAN_STATISTICS*/ * FROM r
UNION ALL
SELECT * FROM film
WHERE length = 130
AND NOT EXISTS (
SELECT * FROM r
);
SELECT p.*
FROM (
SELECT *
FROM v$sql
WHERE upper(sql_text) LIKE '%LENGTH = 120%'
ORDER BY last_active_time DESC
FETCH NEXT 1 ROW ONLY
) s
CROSS APPLY TABLE(dbms_xplan.display_cursor(
sql_id => s.sql_id,
format => 'ALLSTATS LAST'
)) p;
---------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows |
---------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 9 |
| 1 | UNION-ALL | | 1 | | 9 |
|* 2 | TABLE ACCESS FULL | FILM | 1 | 7 | 9 |
|* 3 | FILTER | | 1 | | 0 |
|* 4 | TABLE ACCESS FULL| FILM | 0 | 7 | 0 |
|* 5 | TABLE ACCESS FULL| FILM | 1 | 2 | 1 |
---------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("LENGTH"=120)
3 - filter( IS NULL)
4 - filter("LENGTH"=130)
5 - filter("LENGTH"=120)
While the estimates are off just as in PostgreSQL (an error that can propagate, see conclusion), the actual rows for the second subquery is zero, and the second subquery is run zero times (“Starts”), because we don’t have to really access it at all. Excellent. Exactly what we expected!
Here, I’ve finally created a benchmark that anonymises the results properly by normalising them in order to comply with Oracle’s forbidding of publishing benchmark results. The fastest execution time is simply 1, and the other execution times are multiples of that value:
SET SERVEROUTPUT ON
CREATE TABLE results (
run NUMBER(2),
stmt NUMBER(2),
elapsed NUMBER
);
DECLARE
v_ts TIMESTAMP WITH TIME ZONE;
v_repeat CONSTANT NUMBER := 2000;
BEGIN
-- Repeat benchmark several times to avoid warmup penalty
FOR r IN 1..5 LOOP
v_ts := SYSTIMESTAMP;
FOR i IN 1..v_repeat LOOP
FOR rec IN (
SELECT * FROM film WHERE length = 120
) LOOP
NULL;
END LOOP;
END LOOP;
INSERT INTO results VALUES (r, 1,
SYSDATE + ((SYSTIMESTAMP - v_ts) * 86400) - SYSDATE);
v_ts := SYSTIMESTAMP;
FOR i IN 1..v_repeat LOOP
FOR rec IN (
WITH r AS (
SELECT * FROM film WHERE length = 120
)
SELECT * FROM r
UNION ALL
SELECT * FROM film
WHERE length = 130
AND NOT EXISTS (
SELECT * FROM r
)
) LOOP
NULL;
END LOOP;
END LOOP;
INSERT INTO results VALUES (r, 2,
SYSDATE + ((SYSTIMESTAMP - v_ts) * 86400) - SYSDATE);
END LOOP;
FOR rec IN (
SELECT
run, stmt,
CAST(elapsed / MIN(elapsed) OVER() AS NUMBER(5, 4)) ratio
FROM results
)
LOOP
dbms_output.put_line('Run ' || rec.run ||
', Statement ' || rec.stmt ||
' : ' || rec.ratio);
END LOOP;
END;
/
DROP TABLE results;
The result being (query 1 succeeds, no index):
Run 1, Statement 1 : 1
Run 1, Statement 2 : 1.26901
Run 2, Statement 1 : 1.10218
Run 2, Statement 2 : 1.08792
Run 3, Statement 1 : 1.26038
Run 3, Statement 2 : 1.09426
Run 4, Statement 1 : 1.2245
Run 4, Statement 2 : 1.10829
Run 5, Statement 1 : 1.07164
Run 5, Statement 2 : 1.18562
Or in the inverse case (query 1 fails, no index):
Run 1, Statement 1 : 1
Run 1, Statement 2 : 1.17871
Run 2, Statement 1 : 1.07377
Run 2, Statement 2 : 1.12489
Run 3, Statement 1 : 1.05745
Run 3, Statement 2 : 1.13711
Run 4, Statement 1 : 1.11118
Run 4, Statement 2 : 1.23508
Run 5, Statement 1 : 1.08535
Run 5, Statement 2 : 1.11271
Adding an index doesn’t change much (query 1 succeeds):
Run 1, Statement 1 : 1.20699
Run 1, Statement 2 : 1.28221
Run 2, Statement 1 : 1
Run 2, Statement 2 : 1.21174
Run 3, Statement 1 : 1.0054
Run 3, Statement 2 : 1.2643
Run 4, Statement 1 : 1.0491
Run 4, Statement 2 : 1.31103
Run 5, Statement 1 : 1.02547
Run 5, Statement 2 : 1.23192
Yet, when query 1 fails:
Run 1, Statement 1 : 1.56287
Run 1, Statement 2 : 1.09471
Run 2, Statement 1 : 1.22219
Run 2, Statement 2 : 1.11227
Run 3, Statement 1 : 1.19739
Run 3, Statement 2 : 1.03929
Run 4, Statement 1 : 1.13503
Run 4, Statement 2 : 1
Run 5, Statement 1 : 1.14289
Run 5, Statement 2 : 1.01919
This time, the combined query is a bit faster!
As can be seen, both queries are executed in roughly the same time on Oracle 12c although again the single query seems to be a little bit slower, but not always.
Which is an important reminder to do benchmarking properly! Meaning:
- Repeat benchmarks several times
- Beware of warmup penalties (the first run is often the slowest)
- Beware of excessive caching effects in benchmarks
- Don’t trust performance differences that aren’t significant
- Don’t compile any Scala code or chat on Slack while benchmarking. Your system should be idle, otherwise
- Remember to benchmark the right data set. We only have 600 films in this table. What would happen with 60 million films?
SQL Server
Same exercise again:
DECLARE @ts DATETIME;
DECLARE @repeat INT = 2000;
DECLARE @r INT;
DECLARE @i INT;
DECLARE @dummy VARCHAR;
DECLARE @s1 CURSOR;
DECLARE @s2 CURSOR;
DECLARE @results TABLE (
run INT,
stmt INT,
elapsed DECIMAL
);
SET @r = 0;
WHILE @r < 5
BEGIN
SET @r = @r + 1
SET @s1 = CURSOR FOR
SELECT title FROM film WHERE length = 120;
SET @s2 = CURSOR FOR
WITH r AS (
SELECT * FROM film WHERE length = 120
)
SELECT title FROM r
UNION ALL
SELECT title FROM film
WHERE length = 130
AND NOT EXISTS (
SELECT * FROM r
);
SET @ts = current_timestamp;
SET @i = 0;
WHILE @i < @repeat
BEGIN
SET @i = @i + 1
OPEN @s1;
FETCH NEXT FROM @s1 INTO @dummy;
WHILE @@FETCH_STATUS = 0
BEGIN
FETCH NEXT FROM @s1 INTO @dummy;
END;
CLOSE @s1;
END;
DEALLOCATE @s1;
INSERT INTO @results VALUES (@r, 2, DATEDIFF(ms, @ts, current_timestamp));
SET @ts = current_timestamp;
SET @i = 0;
WHILE @i < @repeat
BEGIN
SET @i = @i + 1
OPEN @s2;
FETCH NEXT FROM @s2 INTO @dummy;
WHILE @@FETCH_STATUS = 0
BEGIN
FETCH NEXT FROM @s2 INTO @dummy;
END;
CLOSE @s2;
END;
DEALLOCATE @s2;
INSERT INTO @results VALUES (@r, 1, DATEDIFF(ms, @ts, current_timestamp));
END;
SELECT 'Run ' + CAST(run AS VARCHAR) +
', Statement ' + CAST(stmt AS VARCHAR) +
': ' + CAST(CAST(elapsed / MIN(elapsed) OVER() AS DECIMAL(10, 5)) AS VARCHAR)
FROM @results;
The result, this time, is more drastic (no index, query 1 succeeds):
Run 1, Statement 1: 1.07292
Run 1, Statement 2: 1.35000
Run 2, Statement 1: 1.07604
Run 2, Statement 2: 1.40625
Run 3, Statement 1: 1.08333
Run 3, Statement 2: 1.40208
Run 4, Statement 1: 1.09375
Run 4, Statement 2: 1.34375
Run 5, Statement 1: 1.00000
Run 5, Statement 2: 1.46458
There is a 30% – 40% overhead for the CTE solution over the two query solution. If we don’t find any rows in the first query (no index):
Run 1, Statement 1: 1.08256
Run 1, Statement 2: 1.27546
Run 2, Statement 1: 1.16512
Run 2, Statement 2: 1.27778
Run 3, Statement 1: 1.00000
Run 3, Statement 2: 1.26235
Run 4, Statement 1: 1.04167
Run 4, Statement 2: 1.26003
Run 5, Statement 1: 1.05401
Run 5, Statement 2: 1.34259
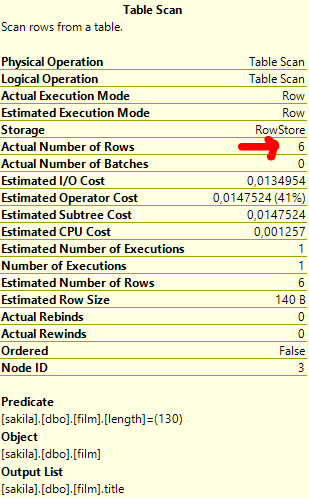
… then the difference is slightly less drastic but still clear. The reason here is that SQL Server doesn’t avoid the unnecessary subquery:

Too bad! (Note I was using SQL Server 2014. Perhaps in 2016, this optimisation is implemented)
Note, you can trust me that adding an index doesn’t change much in this case.
Conclusion
We’ve seen that we can easily solve the original problem with SQL only: Select some data from a table using predicate A, and if we don’t find any data for predicate A, then try finding data using predicate B from the same table.
Oracle and PostgreSQL can both optimise away the unnecessary query 2 by inserting a “probe” in their execution plans that knows whether the query 2 needs to be executed or not. In Oracle, we’ve even seen a situation where the combined query outperforms two individual queries. SQL Server 2014 surprisingly does not have such an optimisation.
While the performance impact was negligible in all benchmarks (even in SQL Server), we should be careful with these kinds of queries and not entirely rely on the optimiser to “get it right”. In all three databases, the cardinality estimates were off. We’re working with small data sets, but if data sets grow larger, and queries like the above are embedded in more complex queries, then the wrong cardinality estimates can easily produce wrong execution plans (e.g. favouring hash join over nested loop joins because of a high number of estimated rows).
An example of this was given in a previous blog post.
Nevertheless, we can get quite far with SQL, without resorting to procedural client languages and if I had conducted my benchmark with a JDBC client instead of procedural blocks directly inside of the database, perhaps the single query would have outperformed the double query case – at least in those cases where query 1 yielded no rows and query 2 had to be executed from a remote client. Probably in Oracle.
Ultimately, I can only repeat myself. Measure! Measure! Measure! There’s no point in guessing. Truth can only be found by measuring actual executions.
 Too bad! (Note I was using SQL Server 2014. Perhaps in 2016, this optimisation is implemented)
Note, you can trust me that adding an index doesn’t change much in this case.
Too bad! (Note I was using SQL Server 2014. Perhaps in 2016, this optimisation is implemented)
Note, you can trust me that adding an index doesn’t change much in this case.
Nice post Lukas. Though you instead of trying the “two query” method, you could do it all in one go by:
1 Finding all the rows for both values
2 Counting how many have the first value
3 If the count is null/zero return the second value, otherwise the first
4 Compare the output of step 3 to the length in the table
For example:
This only access the table once, so I’d expect more consistent performance. And as long as “where length in (v1, v2)” in the first with chooses an index, faster.
Chris, that’s a nifty solution. Someone already proposed it to me on twitter:
https://twitter.com/lukaseder/status/869891902795124737
But it’s much slower than mine! Yours is a bit faster than the one on twitter, but still not as fast (in my benchmark):
With index on length
Without index on length
One reason might be (from what I’ve read in Tony Hasler’s Expert Oracle SQL) is that window functions with
PARTITION BYalways incur a sort operation.Probably, your solution starts outperforming mine when there are tens of different values for length that we might want to query.
Interesting. Yes, the partition by does do a sort.
I general prefer to measure queries in terms of buffer gets as this tracks your I/Os. This reduces the effect of randomness on the benchmark. Though this hides sorts.
Using this measure (set autotrace trace stat in SQL*Plus), the unindexed queries give:
Analytic, 120: 43 gets
Exists, 120: 58 gets
Analytic, 1200: 40 gets
Exists, 1200: 114 gets
Though this changes when you add the index. The analytic is “worst” when searching for length = 120:
Analytic, 120: 43 gets
Exists, 120: 31 gets
Analytic, 1200: 16 gets
Exists, 1200: 24 gets
This is due to the analytic query still full scanning film (on my 12c database).
So as always the answer to “which is faster” is: “it depends” ;)
Thanks for the additional research. Indeed, gets is another way to measure things. I guess it becomes philosophical at that point. I usually prefer wall clock time, although a benchmark is a biased measure of such time. In production, the time might be rather different. And also: This table is really silly with only 600 rows. What would happen if it had 500M rows? In that case, your sort would probably blow up (but in that case, I’d simply run two queries from the client anyway)
Yeah, 600 rows is tiny. How many of those 500M rows would the query actually be accessing? ;)
We should design a benchmark that varies all possible parameters. Then, also, this one doesn’t even have a join
The way I accomplished this in MSSQL may only work in smaller situations but I wanted to try and update a table but if there were no results from the update I wanted to insert
update table set column='0' where column2='0'; if @@ROWCOUNT=0 insert into table (column, column2) Values ('0','0')These are really two queries (i.e. a batch) in SQL Server, not a single SQL query / statement.
This seems to be faster in SQL Server.
Interesting, indeed. This kind of solution was proposed before in the comments, although yours is certainly simpler. Nice one. I can confirm, your solution outperforms the
UNION ALL .. NOT EXISTSone almost as well as running 2 separate queries on my SQL Server 2014 instance:I’m interested in how to create a view which can be queried. If the answer doesn’t exist in the first table, the view should then return all rows of a backup table. I’m sure it’s possible but can’t wrap my noob head around it. On the application side, I can only freely fill in the body of a WHERE clause of a simple SELECT statement to query the view. Is this possible in a view?
I’m not convinced this can be done using a view… The point of this article is to show that some parts of the query will have to be duplicated inside of the query (i.e. view in your case), and those parts are the parts you want to keep outside of the view…
Yeah, I couldn’t find any further information on doing this kind of thing in a view. I appreciate that you take the time to reply here. :o) I’m just doing both queries on the application side. If the first returns no results, then I run the second to get the fallback values.
I’m interested in the same as Nate. When you deal with tables that are remodelled yearly, it’s a necessity to query each table (2017, 2018, 2019…) to find where a record is and then execute an update/insert/delete. The only way I know how to do this now, is to copy everything into a new table, which has the data from all tables.
A function like
“IF EXISTS (SELECT id FROM table_2019 WHERE id = NEW.id) THEN …”
won’t work. It does seem like a noob problem, but I can’t get around it either, so even though the original article isn’t about this, would you care to have a look, lukaseder?
First off, if your database supports partitioning, then use that feature. Otherwise, I’m not sure why you have to worry about this too much. Put a check constraint on the year column in each table, and hope for the optimiser to do-the-right-thing, hoping that the year predicate will be pushed down into the view (you may need to avoid using bind variables on the year column for optimal performance)
Anyway, please ask a question on Stack Overflow about this: https://stackoverflow.com. You will get a more specific answer for your database product, and more people will be able to profit from your question and the answer that you will receive.
That’s very interesting, thanks a lot. I’m reading postgresql’s documentation on partitioning now.
Is there a way to do this in MySQL considering it doesnt support WITH..AS
Yes! You upgrade to MySQL 8! https://dev.mysql.com/doc/refman/8.0/en/with.html
Other than that, just inline the common table expression from WITH to wherever it is used.